I recently came across this blog post where the author talks about a solution for scheduling interdependent tasks. Coincidentally, I have been brushing up Data Structures and Algorithms in preparation for job interviews and realized that the solution discussed in the aforementioned blog could be simplified. That is what I am going to be discussing in this post.
Problem Statement
Given a set of tasks that have dependencies on one another, find an execution order such that depended tasks are executed before their dependents. This is a general class of problems known as the Scheduling Problems that honors a set of constraints, most importantly, the precedence constraints, which specify that certain tasks must be performed before certain others. For example, consider a college student planning a course schedule, under the constraint that certain courses are prerequisite for certain other courses. In the image below, an arrow from course A to course B means A needs to be taken before B.
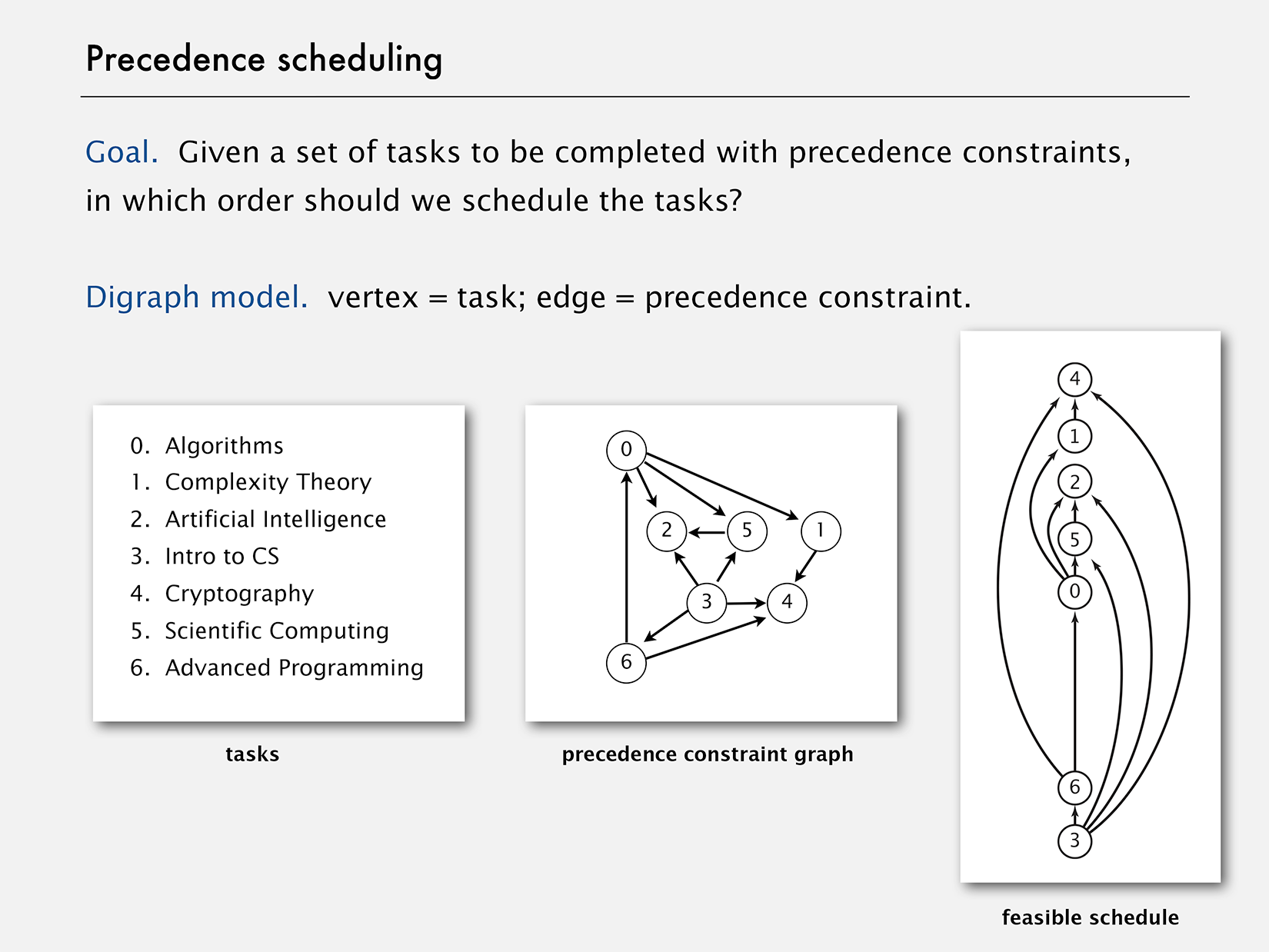
This problem can be solved by sorting the directed graph in the Topological order such that all its edges point from a vertex earlier in the order to a vertex later in the order. A topological order for our example model is shown above.
An obvious prerequisite is that no cycles exist in the graph. Our solution is going to check for cycles though (Trust, but verify).
Design
It occurred to me that a Topological sort is actually not necessary, because the dependencies of a task are fixed at its construction time. The original solution needed the sort because the task scheduler attempted to figure out which tasks needed to run before others; instead, we can simplify the design such that each task notifies its dependents on its completion. Think of it like a Domino effect; once started, the process would progress on its own. Referring to the previous example, Scientific Computing would notify Artificial Intelligence when it is completed, Complexity Theory would notify Cryptography, and so on and so forth.
That is where the Observer Pattern comes in.
Implementation
I make heavy use Java 8 Stream and concurrency constructs, so if you are not familiar with those, you may want to brush up on those before reading further.
Task
Java supports the Observer Pattern in two ways:
-
Using
ObserverandObservable. -
Using
PropertyChangeSupportandPropertyChangeListener.
I chose the latter because the former has been deprecated in Java 9; see the
Observable Javadoc for details.
All we need to do in a task is keep track of the completion of its dependencies.
When all the tasks it depends on have completed, the task starts execution,
and on completion, notifies its dependents. Here’s the Task class
snippet:
public final class Task<V> implements PropertyChangeListener {
private final String id;
private final PropertyChangeSupport support;
private final Collection<Task<V>> dependsOn;
private final Function<Map<String, V>, V> action;
private final Executor executor;
private final Map<String, V> resultMap;
private Task(...) {
this.id = id;
this.dependsOn = dependsOn;
this.action = action;
this.executor = executor;
this.support = new PropertyChangeSupport(this);
this.resultMap = new ConcurrentHashMap<>();
this.dependsOn.forEach(d -> d.addDependent(this));
}
public static <T> TaskBuilder<T> builder() {
return new TaskBuilder<>();
}
@SuppressWarnings("unchecked")
void addDependent(PropertyChangeListener dependent) {
support.addPropertyChangeListener(dependent);
if (dependent instanceof Task<?>) {
Collection<Task<V>> dependsOn = ((Task<V>) dependent).dependsOn;
if (!dependsOn.contains(this)) {
dependsOn.add(this);
}
}
}
...
public V result() {
return resultMap.get(id);
}
@Override
@SuppressWarnings("unchecked")
public void propertyChange(PropertyChangeEvent evt) {
String taskId = evt.getPropertyName();
Set<String> ids = dependsOn
.stream()
.map(task -> task.id)
.collect(toSet());
if (!ids.contains(taskId)) {
throw new IllegalStateException(...);
}
resultMap.put(taskId, (V) evt.getNewValue());
if (ids.equals(resultMap.keySet())) {
execute();
}
}
public void execute() {
try {
CompletableFuture.supplyAsync(
() -> action.apply(unmodifiableMap(resultMap)), executor)
.thenAccept(result -> {
resultMap.put(id, result);
support.firePropertyChange(id, null, result);
});
} catch (Exception e) {
e.printStackTrace();
}
}
...
public static final class TaskBuilder<V> {
...
public Task<V> build() {
...
return new Task<>(id, dependsOn, action, executor);
}
}
}
I use the Builder Pattern to provide an elegant means of constructing a task.
The task scheduler simply needs to check if there is a cycle, and if not, submit the tasks that do not depend on others. In order to do that, I use the excellent algs4 library.
public final class TaskScheduler<V> {
private final Map<String, V> resultMap;
private final CountDownLatch latch;
private final List<Task<V>> rootTasks;
...
@SuppressWarnings("unchecked")
public TaskScheduler(List<Task<V>> tasks) {
int v = tasks.size();
Map<String, Integer> taskMap = IntStream.range(0, v)
.mapToObj(i -> new SimpleImmutableEntry<>(tasks.get(i).id(), i))
.collect(toMap(Map.Entry::getKey, Map.Entry::getValue));
Digraph graph = new Digraph(v);
taskMap.forEach((name, idx) -> {
Task<V> task = tasks.get(idx);
task.dependsOn()
.forEach(dependency ->
graph.addEdge(idx, taskMap.get(dependency)));
});
DirectedCycle directedCycle = new DirectedCycle(graph);
if (directedCycle.hasCycle()) {
...
throw new IllegalArgumentException(...);
}
rootTasks = IntStream.range(0, v)
.filter(i -> graph.outdegree(i) == 0)
.mapToObj(tasks::get)
.collect(toList());
resultMap = new ConcurrentHashMap<>();
latch = new CountDownLatch(v);
PropertyChangeListener accumulator = evt -> {
latch.countDown();
resultMap.put(evt.getPropertyName(), (V) evt.getNewValue());
};
tasks.forEach(task -> task.addDependent(accumulator));
}
public Map<String, V> await(long timeout, TimeUnit unit) {
rootTasks.forEach(Task::execute);
latch.await(timeout, unit);
return unmodifiableMap(resultMap);
}
}
Lastly, since we should never write code without writing unit tests (you do not, right?), here is a test:
void testTask() throws InterruptedException {
Random random = new Random();
ExecutorService executor = Executors.newSingleThreadExecutor();
Task<Integer> f1 = Task.<Integer>builder()
.id("f1")
.executor(executor)
.action(resultMap -> {
try {
Thread.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return 0;
})
.build();
Task<Integer> f2 = Task.<Integer>builder()
.id("f2")
.executor(executor)
.action(resultMap -> {
try {
Thread.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
})
.build();
Task<Integer> f3 = Task.<Integer>builder()
.id("f3")
.executor(executor)
.dependsOn(Arrays.asList(f1, f2))
.action(resultMap -> {
try {
Thread.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return resultMap.get("f1") + resultMap.get("f2");
})
.build();
Task<Integer> f4 = Task.<Integer>builder()
.id("f4")
.executor(executor)
.dependsOn(Arrays.asList(f2, f3))
.action(resultMap -> {
try {
Thread.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return resultMap.get("f2") + resultMap.get("f3");
})
.build();
Integer result = new TaskScheduler<>(f1, f2, f3, f4)
.await(30, TimeUnit.SECONDS)
.get("f4");
assertNotNull(result);
assertEquals(2, result.intValue());
}
To finish off, here is a sample execution log:
Task: f1 depends on: []
Task: f2 depends on: []
Task: f3 depends on: [f1, f2]
Task: f4 depends on: [f2, f3]
Task: f1 is executing on thread: pool-1-thread-1
Received notification from task: f1 inside task: f3
Task: f3 is not ready
Task: f2 is executing on thread: pool-1-thread-1
Received notification from task: f2 inside task: f3
Task: f3 is ready to be executed
Received notification from task: f2 inside task: f4
Task: f4 is not ready
Task: f3 is executing on thread: pool-1-thread-1
Received notification from task: f3 inside task: f4
Task: f4 is ready to be executed
Task: f4 is executing on thread: pool-1-thread-1
Conclusion
I believe a good solution is deceptively simple, and therein lies its elegance. For a production-grade solution, I would have robust exception handling, but for a proof-of-concept like this, I did not spend much time with that.
]]>